.svg)




Theory only takes understanding so far. Seeing query fan-out traced through a real scenario — from a single user query to the sub-queries generated, the sources retrieved, and the specific reasons those sources were selected — makes the mechanics concrete and the optimisation implications immediately clear.
This article walks through one end-to-end example: a B2B buyer asking about project management software for remote teams. It is a realistic, high-volume commercial query with enough complexity to trigger meaningful fan-out. The analysis uses documented patterns from Ekamoira, upGrowth, LLMrefs, and Profound to reconstruct how ChatGPT and Perplexity handle this query behind the scenes, and what it means for any brand trying to appear in the response.
The Original Query
“Best project management software for remote teams”
This is a seven-word commercial query. In traditional search, it would trigger a ranked list of pages targeting that phrase. In AI search, it triggers something far more complex.

The query contains multiple embedded signals: a commercial modifier (“best”), a product category (“project management software”), and a use-case qualifier (“for remote teams”). Each signal is a branching point for fan-out. According to Ekamoira’s fan-out analysis of 33,000 queries, e-commerce and software queries like this one generate between 18 and 22 sub-queries per session — the highest fan-out volume of any B2B category. The AI does not look up that seven-word phrase. It breaks the entire intent landscape apart.
AI Expanded Sub-Queries
Based on documented fan-out behaviour from upGrowth’s analysis of 20 million ChatGPT search queries, and Ekamoira’s cross-platform fan-out research, the following table reconstructs the sub-queries this prompt is most likely to generate across ChatGPT and Google AI Mode. ChatGPT issues an average of 2.3–2.8 sub-queries per prompt. Google AI Mode issues 9–11. For a complex commercial query like this one, AI Mode reaches the higher end of that range.
Notice two things about this table. First, the AI has added temporal and commercial modifiers that were not in the original query — "2026", "top rated", "comparison", "free vs paid" — matching what Profound's October 2025 research confirmed: answer engines routinely add these modifier patterns during fan-out to match how buyers actually evaluate options. Second, each sub-query targets a different content type. Comparison pages, review platforms, feature documentation, pricing breakdowns, and use-case articles are all being retrieved simultaneously — from different sources.
One seven-word query. Eight parallel sub-queries. Eight different content types retrieved from eight potentially different domains. A brand with one page addresses one of those eight. A brand with a cluster addresses all of them.
Sources Retrieved
The sources retrieved across these eight sub-queries come from a deliberately diverse pool. AI systems do not retrieve eight results from the same domain. They pull from the source that most specifically and credibly answers each individual sub-query.
For sub-query 1 (best PM software 2026), the AI retrieves from G2, Capterra, and editorial roundup articles on established publications — because these are the sources that have accumulated trust signals for commercial software comparisons. For sub-query 2 (collaboration features), it retrieves from product documentation and feature comparison guides — because those are factually precise and structured for extraction. For sub-query 6 (reviews 2026), it pulls from review aggregators and community platforms because recency and social proof signals are highest there.

Perplexity’s citation behaviour is particularly instructive here. As Search Engine Land’s query fan-out guide notes, Perplexity previously made its intermediate retrieval steps visible to users — showing the multiple focused searches it executed before assembling the final answer. Those steps followed exactly this pattern: different sub-queries routed to different source types, each selected for a specific kind of credibility. The product’s brand website would appear for sub-query 2 or 5. G2 would appear for sub-query 1 or 6. An independent buyer’s guide would appear for sub-query 4. The synthesised response draws from all of them.
Why Those Sources Were Selected
Source selection is not random and it is not purely based on domain authority. It is based on which source provides the most extractable, credible, directly answerable passage for each specific sub-query. Four selection criteria are consistently at work:

Passage extractability. The selected source contains a section that directly answers the sub-query without requiring surrounding context. A pricing page that opens with “Project management software typically costs between $3 and $5 per user per month for small teams, rising to $8–12 for enterprise features” is more extractable than one that buries the figure in paragraph four.
Source authority for that intent type. G2 is trusted for reviews. G2 is not trusted for technical integration documentation. The AI routes different sub-queries to different source types based on learned associations between domains and content categories. A brand’s own website earns authority for definitional and feature sub-queries. Third-party platforms earn authority for evaluation and review sub-queries.
Entity consistency. Sources that describe the brand or product consistently — same name, same feature set, same positioning — across multiple retrieval pathways are cited with higher confidence. Sources that describe the same product differently across pages create disambiguation uncertainty that reduces citation probability.
Freshness. Ahrefs found in 2025 that AI tools cite pages that are 25.7% fresher than those surfaced in traditional search. For a query with a “2026” modifier added during fan-out, a page last updated in 2024 is structurally disadvantaged against a competitor with a visible “Last Updated: February 2026” timestamp and current statistics throughout.
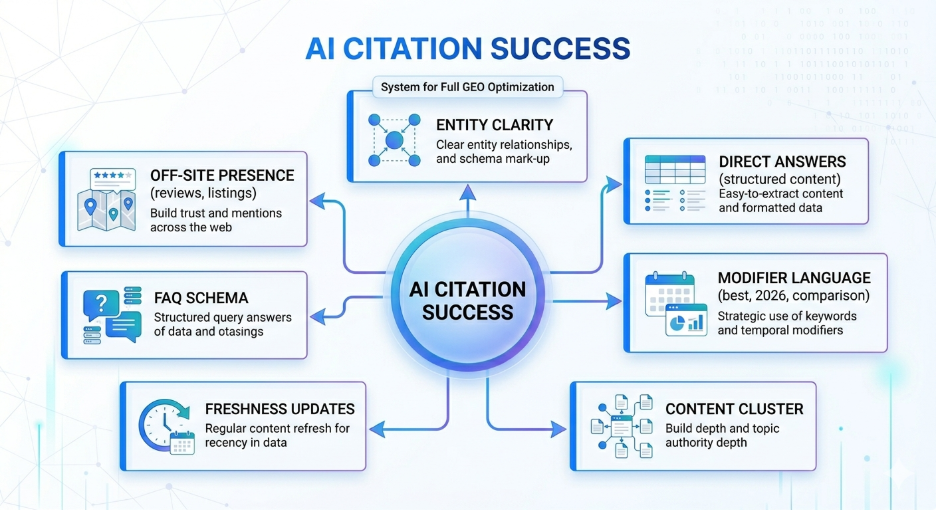
GEO Optimization Breakdown
The following table shows what a brand would need to have in place to earn citations across all eight sub-queries generated from this example, and why each signal directly produces the citation result:
The brand represented in this table is not a hypothetical. ALM Corp’s December 2025 analysis of Stripe’s AI search visibility documents precisely this pattern: Stripe’s comprehensive, well-structured content covering payment processing from every angle helped them significantly outperform competitors in AI search visibility across ChatGPT, Perplexity, Google AI Mode, and Gemini. They did not rank first for a single keyword. They built topical authority across an entire intent network.
The result is citation presence that their competitors cannot replicate with a single optimised page.
Key Learnings
Walking through one example end-to-end produces several specific, actionable conclusions that generalise across any B2B topic or industry:
One query generates a content architecture requirement, not a page brief. A single commercial query like this one demands a pillar article, at minimum six to eight cluster articles, a presence on review platforms, feature documentation, pricing transparency, and regular freshness updates. Treating it as a brief for one page is the wrong starting point.
The AI adds modifiers you did not target. The original query contains no year reference, no comparison signal, no review language. The AI adds all of these during fan-out. Content that does not naturally contain these modifiers will not match the expanded sub-queries. Auditing existing content for modifier coverage is as important as creating new content.
Platform diversity is a retrieval advantage. G2, Capterra, and independent publications are retrieved for sub-queries your own website will never rank for. Building presence on these platforms is not a bonus. It is a structural requirement for earning citations across the full fan-out of any commercial query.
Freshness is a selection filter, not a ranking signal. AI systems are not penalising old content in a ranking sense. They are actively selecting fresher sources when temporal modifiers appear in sub-queries. Any page targeting a commercial category that includes a year modifier in the sub-queries it generates needs a current-year update to remain competitive.
Cluster architecture multiplies citation probability within a single session. Because fan-out generates multiple sub-queries simultaneously, a brand with a cluster of content addressing all angles earns multiple citation opportunities within one user interaction. The probability of appearing in the final synthesised response compounds with each sub-query your cluster addresses. This is why topical authority building — not single-page optimisation — is the correct structural response to how AI search actually works.
Query fan-out is not a theory. It is the live mechanism that decided, right now, which brands appeared in the answer to “best project management software for remote teams” across ChatGPT and Perplexity. The brands that understood the mechanism built for it. The brands that did not are invisible in a response that their buyers are already reading.

