.svg)
.svg)

LLM Optimization: The Complete 2026 Guide
How to shape what large language models know, retrieve, believe, and say about your brand across ChatGPT, Perplexity, Gemini, Claude, and Copilot.
Updated June 2026: refreshed LLM source-mix data, LLM recommendation-rate framework, brand-signal guidance, RAG vs training-data strategy, and practical LLMO audit steps.
There is a question most brands never think to ask: what does ChatGPT actually believe about us?
Not what your website says. Not what your Google ranking implies. What matters now is how a large language model understands your brand, your category, your competitors, and your place in the market when a buyer asks for advice.
LLM Optimization, or LLMO, is the discipline of shaping what models know from training data, what they retrieve in real time, and how they represent a brand in synthesized answers.
This guide explains how LLMs select what to mention, which signals move citation frequency, how platform source behavior differs, and how to build a practical LLMO program without abandoning SEO, GEO, or AEO.

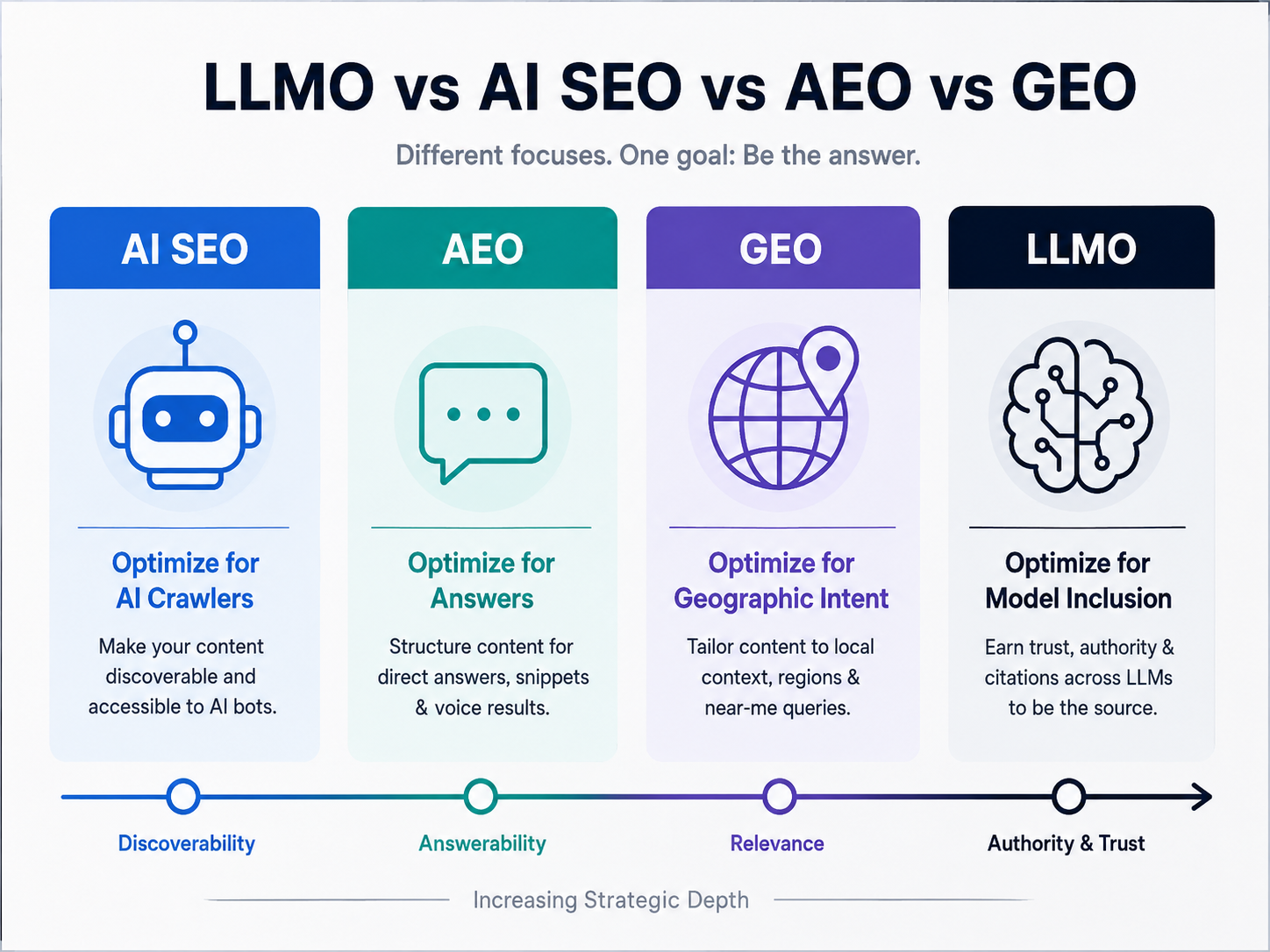
What Is LLM Optimization?
Direct answer: LLM Optimization is the practice of improving a brand’s visibility, citation frequency, description accuracy, and recommendation rate inside large language model responses by influencing both model training knowledge and live retrieval sources.
LLMO sits beside three related disciplines. Large language models understand content through patterns, entities, context, retrieval, and synthesis. AI SEO makes content reachable by crawlers. AEO structures content for direct answers. GEO builds entity trust. LLMO manages the broader information ecosystem that shapes what models know and say.
| Layer | Discipline | Primary target | Timeline |
|---|---|---|---|
| Technical access | AI SEO | Crawler access, indexability, rendering | Days to weeks |
| Answer extraction | AEO | Snippets, PAA, voice, direct answers | Weeks to months |
| Entity authority | GEO | Brand credibility across AI citation systems | Months |
| Knowledge shaping | LLMO | What LLMs know, believe, and say | Months, compounding |
AI SEO
AEO
LLMO
Why LLM Optimization Matters in 2026
LLM-referred visitors are often more qualified because the model has already done part of the research, comparison, and shortlisting before the click. The Word file cites Seer Interactive’s LLM conversion benchmark showing ChatGPT visitor conversion at 15.9% versus 1.76% from standard organic search.
The commercial implication is simple: if your brand appears in the answer, the user arrives with context. If your brand does not appear, you may be excluded before the website visit ever happens.

The risk is equally direct. The guide notes that many AI citations come from URLs outside the organic top 20, meaning a brand can rank well in Google and still fail inside LLM shortlists.
“Brand search volume is becoming an LLMO signal because awareness, mentions, and demand all teach models which brands are real, relevant, and safe to recommend.”
— AI Recommended LLM visibility principleHow Large Language Models Actually Select What to Mention
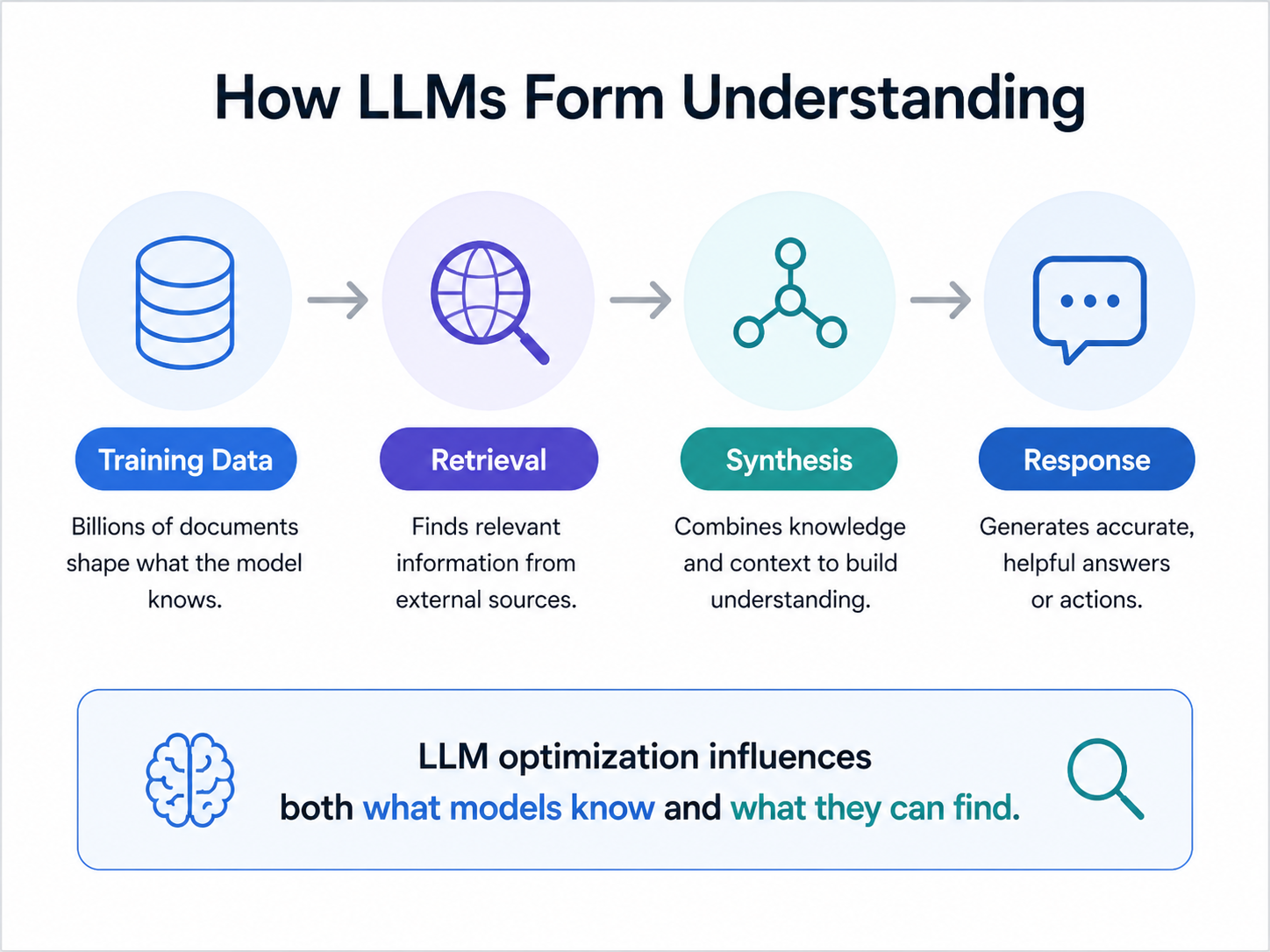
LLMs use two different knowledge layers. The first is parametric memory: information encoded during model training. The second is retrieval-augmented generation, or RAG: live information fetched when a user asks a question.
Parametric knowledge is slow to change but durable. RAG is faster, because a new article, Reddit thread, LinkedIn post, or review profile can influence live retrieval within days. A strong LLMO program needs both: the durable lane and the fast lane.
| Memory type | How it works | Update speed | Key lever |
|---|---|---|---|
| Parametric | Encoded into model weights during training | Months | Wikipedia, Wikidata, authoritative publications, long-term entity consistency |
| RAG / retrieval | Live web search at query time | Hours to days | Structured content, earned media, Reddit, LinkedIn, reviews, fresh citations |
For deeper support, this connects directly with semantic SEO for LLMs, embeddings and vector search optimization, and content chunking for LLM SEO.
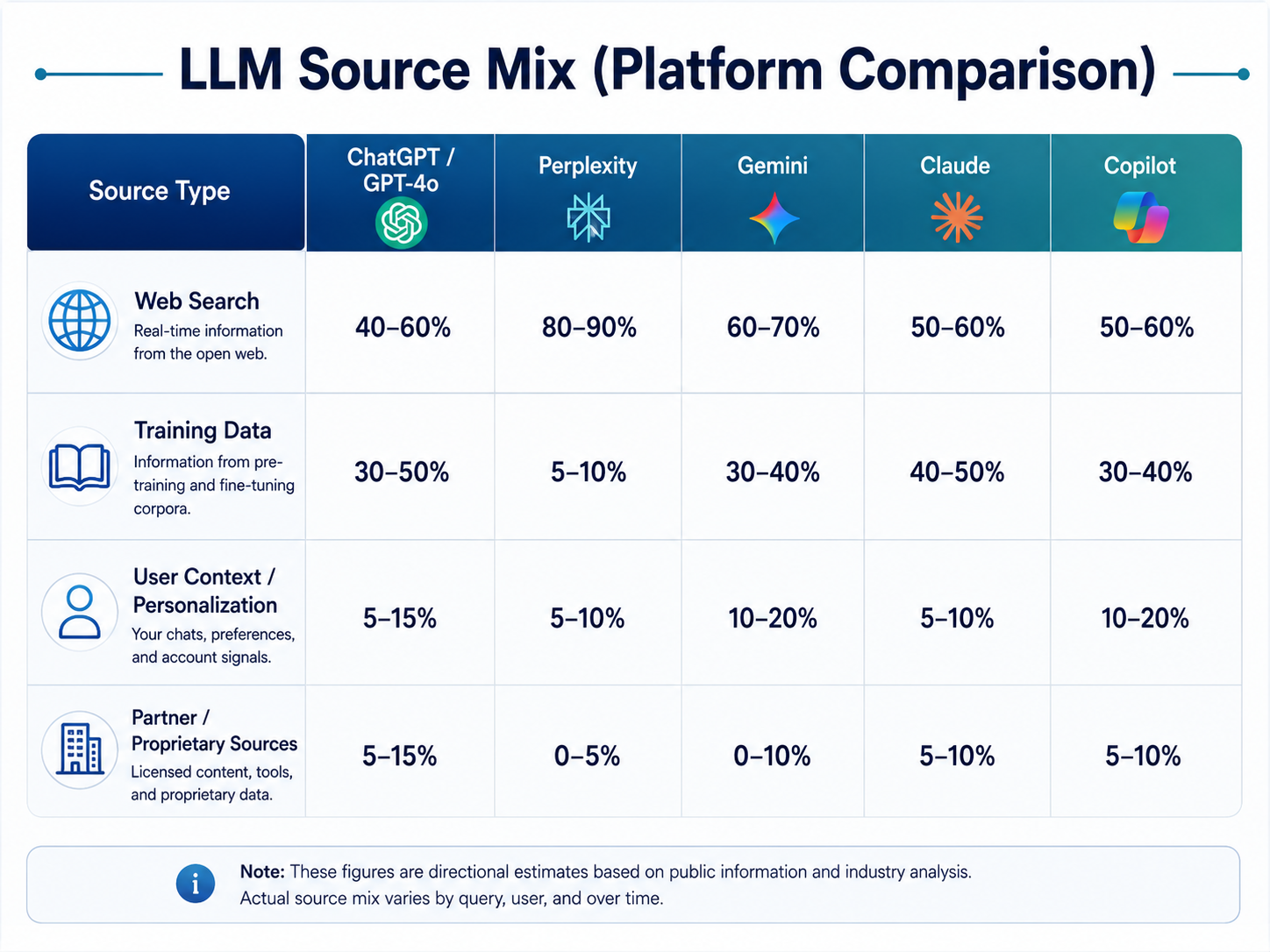
Platform Citation Patterns: Where Each LLM Gets Sources
One of the most important LLMO lessons is that each platform has a different source mix. ChatGPT, Perplexity, Gemini, Claude, and Copilot do not all pull from the same places with the same weight.
That means a brand cannot optimize for “AI” in general. It needs platform-specific tactics based on where each model tends to retrieve and cite information.
Brand Signals That Influence LLMs
LLMs look for patterns of trust, relevance, and consistency across the open web. A brand described consistently on its own site, LinkedIn, review profiles, community discussions, and credible publications gives models more confidence.
Third-party corroboration matters because models do not want to rely only on what a brand says about itself. They need external proof that the brand is real, known, and relevant to a category.

For implementation, this connects with entity and brand signal optimization for LLM SEO. The goal is not to create noise everywhere. The goal is consistent, verifiable presence in the places LLMs actually use.
The Five Levers of LLM Optimization
1. Wikipedia and knowledge graph presence
Wikipedia and Wikidata can shape parametric knowledge because they appear widely in training corpora and knowledge graphs. The standard is strict: neutral language, third-party sources, and factual consistency.
2. Earned media in LLM-cited publications
Strategic PR matters more when it targets sources that LLMs actually retrieve and cite. One credible article in a high-authority source can be more useful than many low-context mentions.
3. Reddit and community presence
Reddit, forums, and community conversations help models understand how real users discuss the brand and category. Promotional noise does not help; authentic expertise does.
4. LinkedIn expert content
Founder-led and expert-led LinkedIn content can become a citation asset for professional queries. The strongest posts explain mechanisms, share data, and use clear expert framing.
5. Review and rating profiles
Trustpilot, G2, Capterra, Gartner Peer Insights, and category-specific directories act as corroboration signals. They help LLMs verify that the entity exists beyond its own website.
How to Structure Content for LLM Retrieval
LLMs do not always retrieve full pages. They often retrieve passages, chunks, and answer blocks. That means content architecture for LLMO is really chunk architecture.
A strong chunk should answer one question clearly, include specific facts, avoid vague claims, and make sense without needing the entire page around it.
Practical LLMO content also includes prompt-based discovery. Instead of only mapping keywords, teams should map the prompts, follow-up questions, and comparison pathways that users ask LLMs.
Brand Narrative Shaping: The Long Game
LLMs do not only cite brands. They describe them. The model may call a brand “emerging,” “enterprise-focused,” “best for small teams,” or “known for a specific use case.” Those descriptions shape buyer perception.
Narrative shaping means correcting inaccurate AI descriptions through owned content, author pages, third-party sources, LinkedIn expertise, PR, reviews, and consistent entity data.
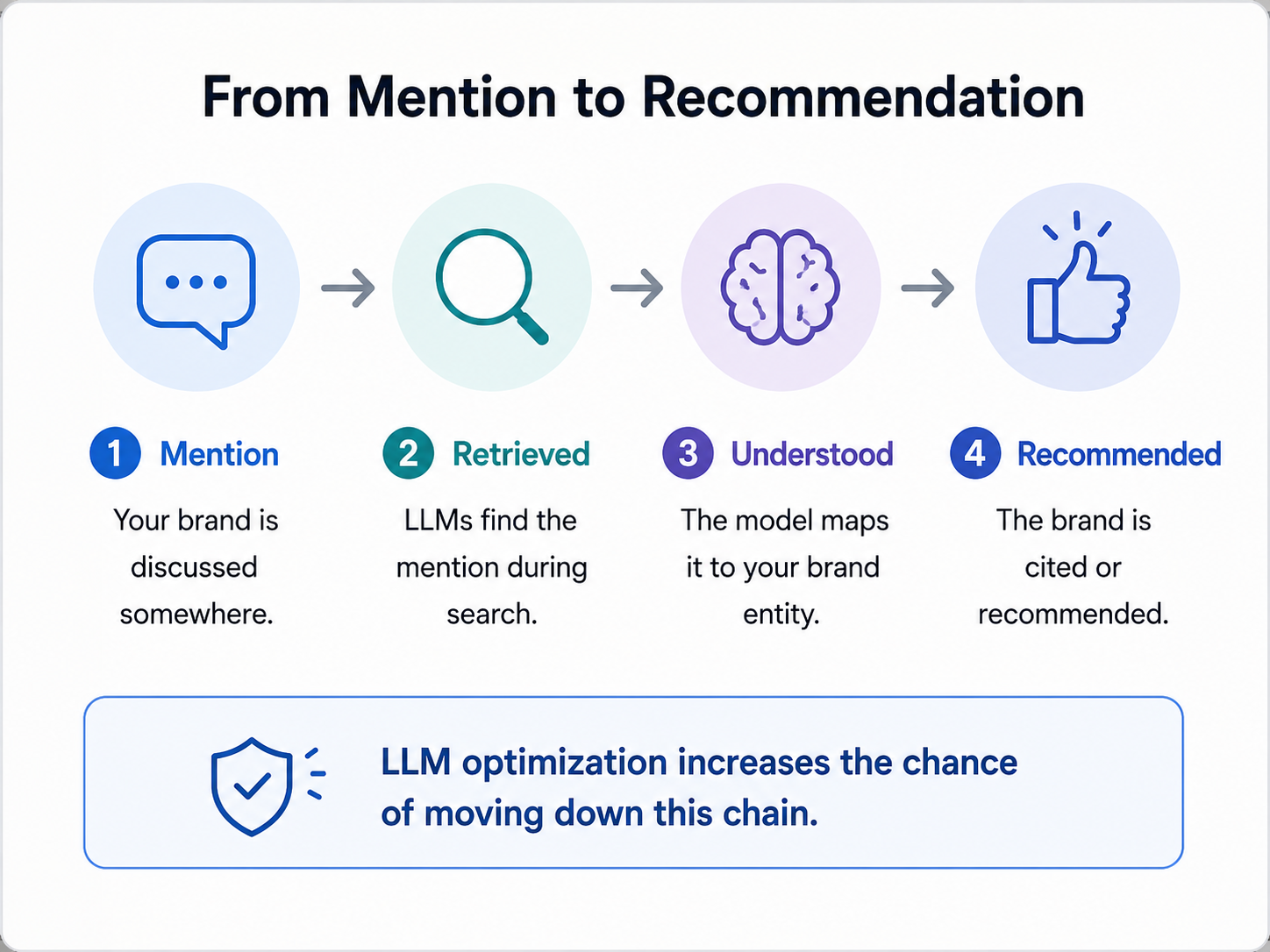
The first step is to run brand and category queries across ChatGPT, Perplexity, Gemini, Claude, and Copilot. Record how each model describes the brand, which competitors it names, and where the description is incomplete or outdated.
How to Measure LLM Optimization Performance
Traditional rank tracking does not measure LLM visibility. A brand can rank well in Google and still be absent from AI-generated responses. LLMO needs a different measurement system.
The core metric is LLM Recommendation Rate: the percentage of relevant AI-generated responses where the brand is mentioned, cited, or recommended across a consistent set of target prompts.
| Metric | What it measures | How to track it |
|---|---|---|
| LLMR | % of responses mentioning the brand | Run 20–50 target queries monthly across major LLMs |
| Share of voice | Brand mentions vs competitors | Track competitors in the same prompt set |
| Description accuracy | Whether the model describes the brand correctly | Review recorded responses manually |
| Platform citation rate | Which engines cite the brand | Split LLMR by ChatGPT, Perplexity, Gemini, Claude, Copilot |
| AI referral quality | Whether LLM-referred users convert | Segment GA4 by referral source |
Use the same prompts every month. Individual LLM answers can vary, so one response is not enough. Treat measurement like polling: repeated samples create a clearer picture than a single test.
How to Build an LLMO Program
Month 1: Baseline audit
Run 20–50 target queries across major LLMs. Record brand mentions, competitor mentions, source citations, and description accuracy. Audit Wikipedia, Wikidata, review platforms, LinkedIn, Reddit, and crawler access.
Months 2–3: Structural fixes
Restructure top pages with BLUF openings, source-backed statistics, FAQ sections, internal links, and author proof. Build LinkedIn expert content and begin targeted earned media in LLM-cited sources.
Months 4–12: Compounding
Track LLMR monthly, update content freshness, add audience-specific pages, expand third-party mentions, and correct inaccurate model descriptions through content and earned media.
Common LLM Optimization Mistakes
Content-only thinking: Owned content is necessary, but LLMs often cite and trust third-party sources. Wikipedia, Reddit, LinkedIn, review platforms, and trusted publications matter.
Single-response measurement: LLM outputs vary. Do not make strategy decisions from one ChatGPT answer. Measure statistically across repeated prompt samples.
Same strategy for every platform: ChatGPT, Perplexity, Gemini, Claude, and Copilot do not use the same source mix. Platform-specific strategy matters.
Promotional Wikipedia writing: Wikipedia must be neutral and third-party sourced. Promotional edits create risk, not authority.
Ignoring description accuracy: A brand cited incorrectly may create more confusion than no citation at all.
Where LLM Optimization Is Heading
LLMO is moving from answer visibility toward agentic visibility. As AI agents compare, shortlist, purchase, and recommend on behalf of users, brands need to be present before the decision is made.
The future of LLMO is not only being cited. It is being accurately understood, safely recommended, and consistently included when AI systems make decisions for users.
Multilingual citation patterns will also diverge. Global brands will need language-specific and market-specific LLMO strategies, not one English-language strategy copied across regions.
Frequently Asked Questions
What is LLM Optimization?
LLM Optimization is the practice of improving a brand’s citation frequency, description accuracy, and recommendation rate inside large language model responses.
How is LLMO different from GEO and AEO?
GEO builds entity authority and citation trust. AEO structures content for direct answer extraction. LLMO shapes what the model knows, retrieves, and says about a brand.
What is LLM Recommendation Rate?
LLMR is the percentage of relevant AI-generated responses where a brand is mentioned, cited, or recommended across a fixed set of target prompts.
How long does LLMO take?
Retrieval improvements can appear in 30–90 days. Parametric improvements take longer, often 6–12 months, because they depend on model training cycles and durable source presence.
Can a small brand compete in LLMO?
Yes. LLMs reward specificity. A smaller brand with deep authority in one niche can earn citations for specialized prompts even against larger general competitors.
Key Takeaways
- LLMO is the knowledge-shaping layer of AI visibility.
- It works across both parametric memory and live retrieval.
- Third-party proof, author credibility, community mentions, and review profiles matter.
- Content should be structured into clear, extractable chunks.
- LLMO should be measured with LLM Recommendation Rate, source share, and description accuracy.

About the Author
Marcus Hibbert is the founder of AI Recommended, where he focuses on LLM Optimization, Generative Engine Optimization, Answer Engine Optimization, AI search visibility, structured data, and brand discoverability across ChatGPT, Perplexity, Gemini, Claude, Copilot, and Google AI experiences.
Connect with Marcus on LinkedIn.
Request an LLMO Audit
Get a focused review of how large language models describe, cite, retrieve, and recommend your brand across key buyer prompts and AI platforms.
By submitting this form, you’re requesting an LLM optimization visibility review for your brand.
How AI Delivers Direct Answers to Users
A Practical Guide for LLM SEO
How to Build Meaning, Context, and Topical Depth for AI Systems
How LLMs Retrieve Relevant Content
How to Structure Pages for Better AI Retrieval
How AI Models Understand Your Business
How LLMs Recommend Brands, Products, and Services
How to Measure and Improve Your Visibility in Large Language Models
